



When users think of the term ‘computer bug’, they would usually associate it with frozen screens, apps not functioning smoothly, or simply an unexpected crash that may require time for the system to reboot.
Computer bugs are typically described as malfunctions caused by various possible reasons, including coding errors (mistakes in the way a program is written) or design flaws, rather than external factors like malware.
So how did we come to think of bugs as something that could affect our experiences with computers?
On the Smithsonian website, the page “Log Book With Computer Bug” explains that engineers in the United States have been calling small flaws in machines “bugs” for over a century. In an 1878 letter written by Thomas Edison, he referred to “bugs” as “little faults and difficulties” he came across while working on his phonograph, according to a publication from US nonprofit digital library JStor.
Then on Sept 9, 1947, engineers found a moth stuck on one of the components of the Mark II computer at Harvard University. The bug was extracted and then taped into a logbook with the note “first actual case of bug being found”.
According to scholar Fred R. Shapiro in the journal Etymology Of The Computer Bug: History And Folklore, the moth is believed to have “inspired the scientists to speak from then on of debugging the computer, with bug originating as the later back-formation from debug”.
Essentially, while the term “bug” had been used to describe technical glitches long before, the moth incident helped popularise the specific idea of a “computer bug” and cemented “debugging” as part of computing vocabulary.
Failure to launch
Users rarely think about the lines of code running in the background when they interact with apps, websites, or devices. Yet even the smallest error in that code can lead to major problems.
In 1962, the United States National Aeronautics and Space Administration (Nasa) attempted to launch the Mariner 1 spacecraft to get a closer look at Venus. The 202.8kg spacecraft was launched on July 22 but the rocket went off course.
According to Nasa on its website, less than five minutes after takeoff, a Range Safety Officer had to send a destruct command to prevent further mishaps.
An investigation found that part of Mariner 1’s launch failure was due to a hardware issue with the guidance antenna on the Atlas rocket, the launch vehicle carrying the spacecraft. On top of that, a tiny typo in the guidance software caused the system to misread instructions. Instead of using an R with a small overbar to represent radius, the code mistakenly used just ‘R’.
Nasa noted that “the omission was not a hyphen, as is sometimes erroneously reported”.
Why? The New York Times in 1962 ran a story with the headline “For Want of Hyphen Venus Rocket Is Lost”. It also stated that the spacecraft cost US$18.5mil to build. Science fiction author Arthur C. Clarke has also famously described it as “the most expensive hyphen in history” in his 1968 book The Promise Of Space.
Website Fast Company in its report “The Most Expensive Hyphen in History” stated that the incident was a lesson in “care, caution and testing” for the space agency’s computer programmers. Famed Nasa engineer George Mueller reportedly kept a framed image of a hyphen in his office at the time to remind himself that even the smallest details matter.
A second spacecraft Mariner 2 was launched in the same year on Aug 27 and successfully completed its mission to get a close-up of Venus.
Fatal error
In healthcare, technology designed to save lives can pose risks when oversight and testing fall short.
In the mid-1980s, hospitals in the US and Canada began using a machine called the Therac-25 to treat cancer patients with targeted radiation. Unlike earlier models that relied on hardware safety systems, the Therac-25 relied on computer software to control the amount of radiation delivered to patients. It seemed like a leap forward in medical technology.

But in 1986, reports emerged that a computer malfunction had caused the machine to deliver overdoses of radiation to patients. According to the New York Times, two male patients at a Texas cancer treatment centre were overdosed – leading to the death of one of the men – while another such overdose incident in Georgia caused nerve damage in a breast cancer patient.
According to the Times, an investigation into the Georgia case blamed a software glitch involving what was described as an “unforeseen sequence of computer commands”. Dr Kenneth Haile, the then-director of the Kennestone Regional Oncology Center in Marietta, Georgia, explained that typing a certain group of commands into the machine at a rapid rate of speed could result in higher radiation than was called for.
A 1993 investigation paper published by Columbia University reported six known radiation overdose incidents between June 1985 and January 1987 linked to the Therac-25. The paper also revealed that the software was developed by a single programmer and that there was an apparent lack of documentation on software specifications and test plan.
In 1987, the US Food and Drug Administration and its Canadian counterpart ordered all Therac-25 units to be shut down until permanent modifications could be made.
Math not computing
Some bugs could also hit wallets and reputations just as hard. In 1993, Intel unveiled its new Pentium processor, the highly anticipated successor to the Intel 486 chip.
In October 1994, mathematics professor Thomas Nicely discovered that his new system with the Pentium processor occasionally gave the wrong answers when dividing floating-point numbers, which is a type of math used in science and engineering to handle large and precise calculations. He reported the matter to Intel. However, it seemed that Intel did not respond. So approximately a week later, Nicely sent an email to his academic contacts to inform them about the error that he found.
According to the website Tom’s Hardware, the error was due to the chip’s division algorithm. The Pentium had to set aside an array of 2,048 cells, with 1,066 of them holding values between -2 and 2. But Intel made a small yet critical mistake: five of those cells were set to 0 instead of 2, which threw off some calculations.
The flaw, later called the Pentium FDIV bug for ‘floating point division’, wasn’t immediately obvious to everyday users, but it sparked widespread outrage because computers were expected to do math perfectly. Intel initially downplayed the issue, but mounting public pressure forced the company to recall the chips at a cost of nearly US$475mil, making it one of the most expensive hardware bugs in history.
If you’re wondering what happened to some of the chips that the company recalled, they were turned into keychains. According to website Business Insider, the company handed the keychains to employees in 1995, inscribed with a quote by then-CEO Andy Grove: “Bad companies are destroyed by crises; good companies survive them; great companies are improved by them.”
Anticipating the bug
As computers continue to shape how people travel, work, and manage finances, society is also becoming more prepared for potential technology-related challenges.
In the late 1990s, programmers warned that when the year 2000 arrived, many computers – built to store years with just two digits (for example, “99” for 1999) – might read “00” as 1900 instead of 2000, potentially disrupting systems that relied on daily or yearly date calculations. The issue became known as the Y2K bug.
A National Geographic report explained that the Y2K bug could disrupt banks that calculate interest rates daily, power plants that depend on precise computer timings for safety checks, and airlines whose flight schedules could be thrown off if computers failed to display the correct dates. Governments around the world including Malaysia began working on initiatives to prepare for the year 2000 and mitigate any impact the Y2K bug might have.
In 1998, Bernama reported that the Energy, Telecommunications and Posts Ministry had set up a working committee to oversee how companies were gearing up to tackle the Y2K bug. Then‑minister Datuk Amar Leo Moggie (now Tan Sri) said it was “an important issue” to ensure that, when the year 2000 rolled in, utilities like airports and communications services would continue to function as usual. A report by the Economy Ministry stated that a total of RM396mil was allocated to federal and state agencies to prepare for the rollover to year 2000.
In 1999, Bank Negara Malaysia (BNM) said it had released a 66-page report outlining the steps it had taken to ensure that all banks, financial institutions, and insurance companies in Malaysia had implemented Y2K-ready systems. It also shared that ATMs had been tested for Y2K readiness, adding that cash withdrawal services will be available throughout the year and into the year 2000. A Y2K Command Centre was made available to respond to public queries about Y2K issues relating to the banking and financial sector.
When the year 2000 arrived, The Guardian reported that the impact was felt worldwide, noting how 15 nuclear reactors were taken offline, Hawaii experienced power cuts, and over 150 expectant mothers in the United Kingdom were mistakenly given inaccurate Down’s syndrome test outcomes linked to the bug.
Despite these incidents, The Guardian noted that the lasting takeaway was “how few problems actually occurred”, with experts suggesting that the advanced precautions had helped avert major mishaps. The BBC also reported that it was largely business as usual when the year 2000 arrived at midnight.
Similarly, a Jan 1, 2000 report by LifestyleTech (then known as In.Tech) stated that the National Y2K Operations Centre reported no major Y2K-related disruption throughout the country.
Into the blue
As part of a measure to fix bugs and make sure systems stay reliable, software updates are regularly deployed to keep computers safe and running smoothly. But in the case of CrowdStrike, one faulty update triggered widespread chaos.
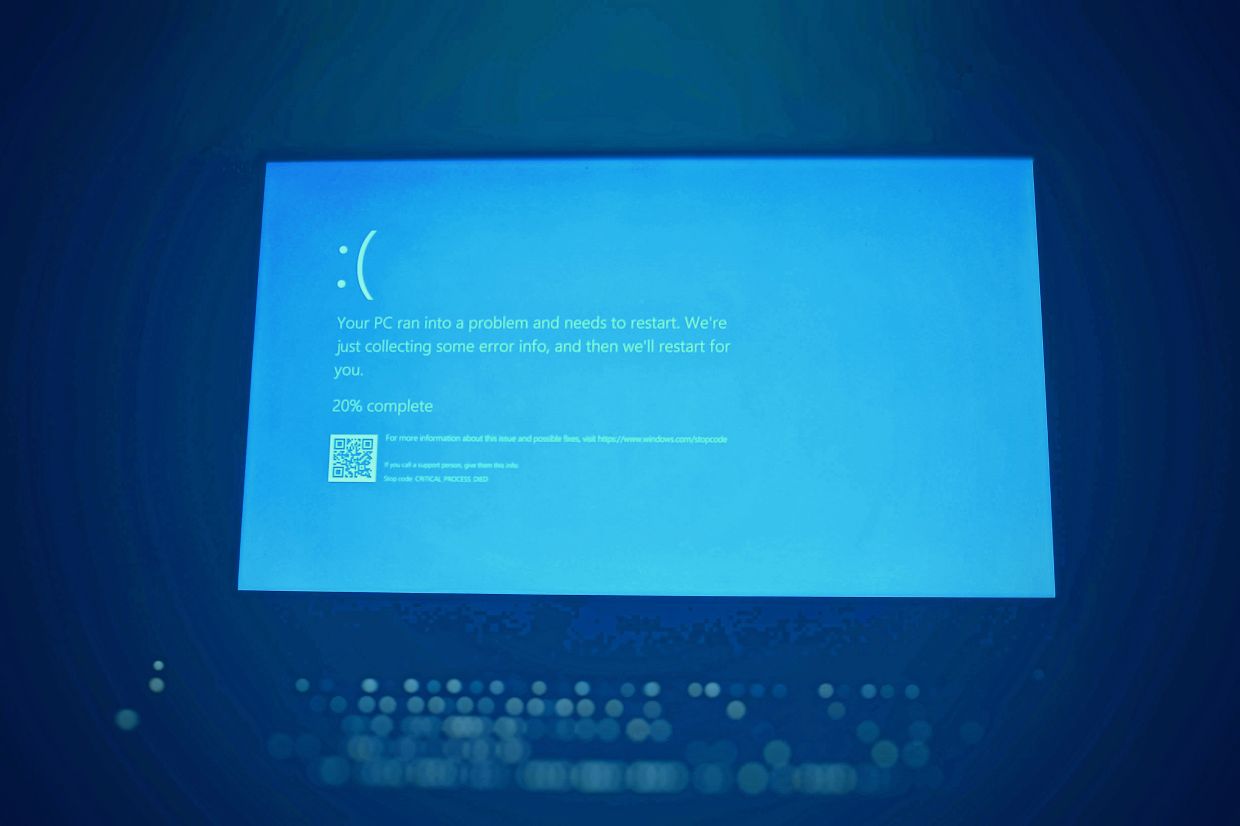
On July 19, 2024, employees around the world including Malaysia reported being affected by the iconic ‘blue screen of death’ or a critical system error screen display on Windows computers. Airlines around the world also reported being impacted by a ‘global IT issue’, with the bug causing flight delays, cancellations, and massive queues at airports as passengers were forced to manually check in, resulting in travel disruptions for countless travellers.
Payment systems, banking and healthcare services were similarly affected, causing long lines at supermarket checkout counters in countries like Australia, the US and New Zealand. Speculation mounted: was the global tech company under cyberattack?
Eventually, American cybersecurity company CrowdStrike confirmed that the outage was caused “by a defect found in Falcon content update for Windows host”, adding that it “was not a cyberattack”. The company also said that it had quickly deployed a fix and begun restoring affected systems.
A Reuters report on July 24, 2024 said the Crowdstrike Falcon software bug affected 8.5 million Windows devices and could result in an estimated US$5.4bil (RM22.83bil) in losses, citing figures from one insurance company. Bernama reported that Digital Minister Gobind Singh Deo said five government agencies and nine companies operating in aviation, banking and healthcare were affected during the Crowdstrike outage.
The issue, he said, highlights the importance of good governance in managing digital platforms.
“Although it was not a cyberattack, the ministry takes this matter seriously. Such disruptions highlight weaknesses in existing IT systems that could lead to significant damage and loss if they recur,” he said.


